
Ready to figure out how Bitcoin resolves the issue of how we can all agree upon a valid single chain of blocks (since any set of nodes in a network can produce a series of timestamped blocks)? If we can all agree upon a single chain of blocks, then we can also all agree on the order of transactions in the network. Any transaction that is not included in this single chain of blocks can then be disregarded. But how can this be accomplished?
In this lesson, we will understand how proof-of-work gives us the answer to this seemingly intractable problem.

Satoshi proposes a proof-of-work system that is similar to Adam Back’s Hashcash (which we learned about in Early Digital Cash Predecessors).
“we will need to use a proof- of-work system similar to Adam Back’s Hashcash”
There are various approaches to achieving consensus on the valid chain. Conventional consensus algorithms have existed for decades. The algorithms required knowing every node in the network and every node communicating with every other node. Moreover, a majority of the nodes in the peer-to-peer network needed to be online to make the system work. Simply put, that setup is far too complicated. It doesn’t scale well and also doesn’t work in open, permissionless systems where any node can join and leave the network at any time.
The brilliance of Satoshi’s proof-of-work is that instead of every node agreeing on the next block, all of the nodes agree on the probability of the next block being correct. Moreover, as we discussed in a previous lesson, Bitcoin’s proof-of-work does not require all nodes to be online. It just requires enough nodes to be online such that the next proof-of-work solution can be solved.
In order for a new block of transaction to be added to the existing chain, a valid hash has to be produced by one of the nodes in the network.
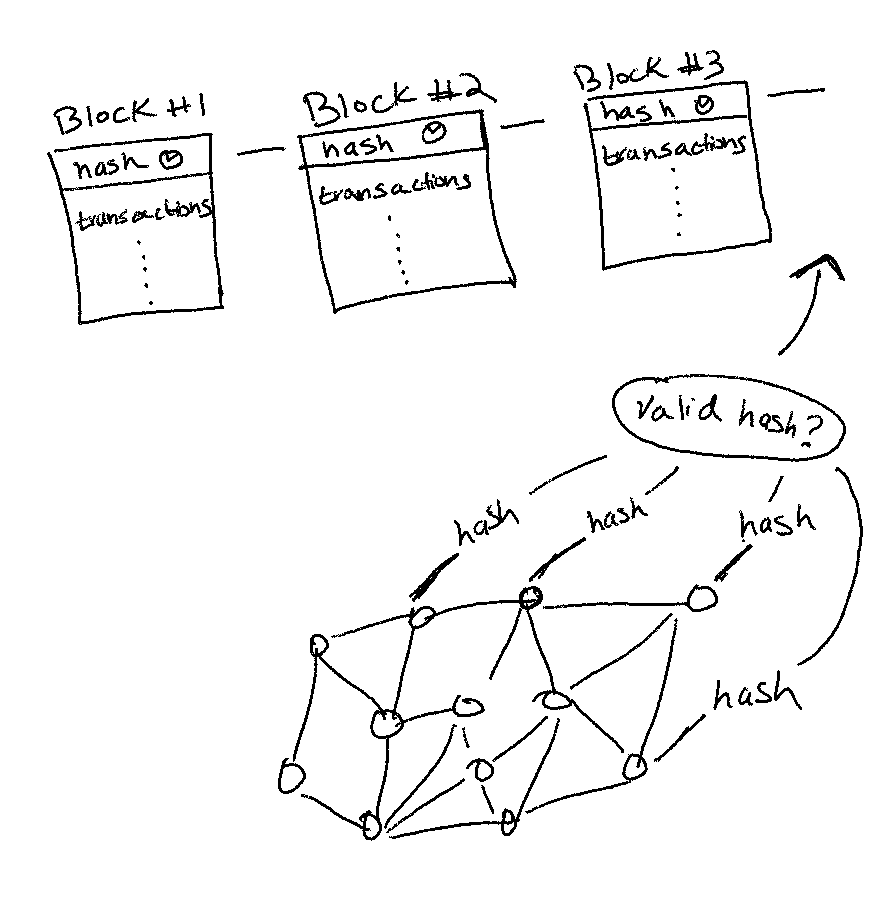
As we learned in the previous post, each new block hash is produced by combining the previous hash and the transactions in the current block. In addition, the hash also includes a number called the “nonce.”
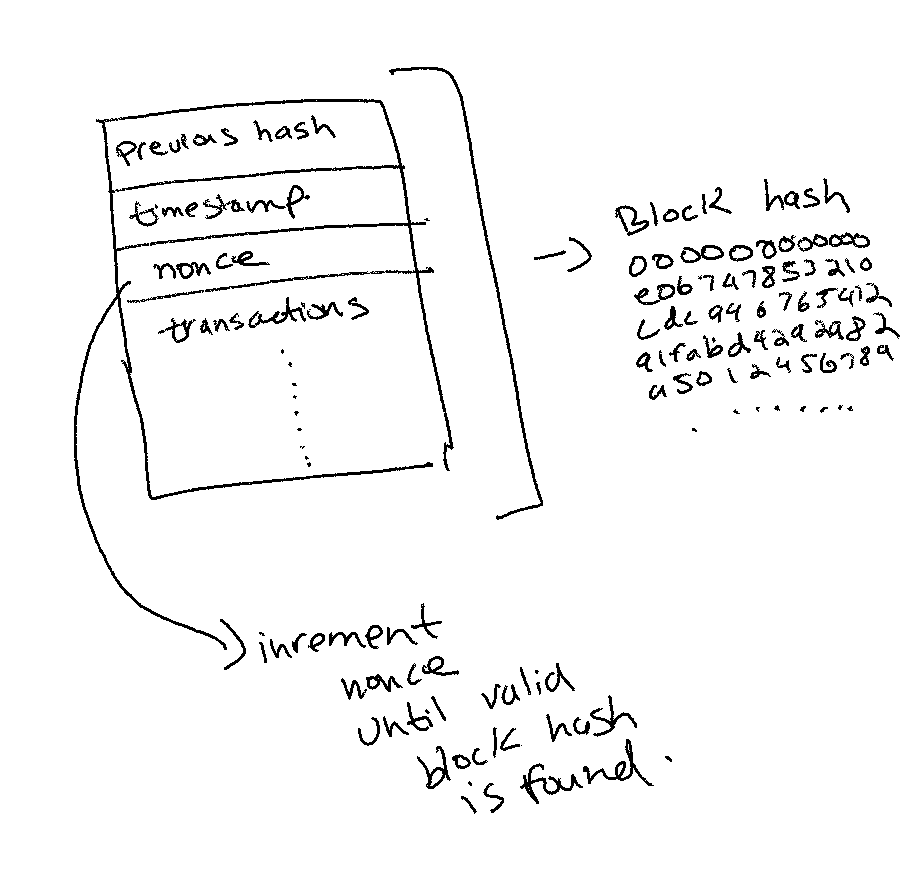
Nodes will keep incrementing this nonce value until one of them produces a hash that has the required number of zero bits in front.
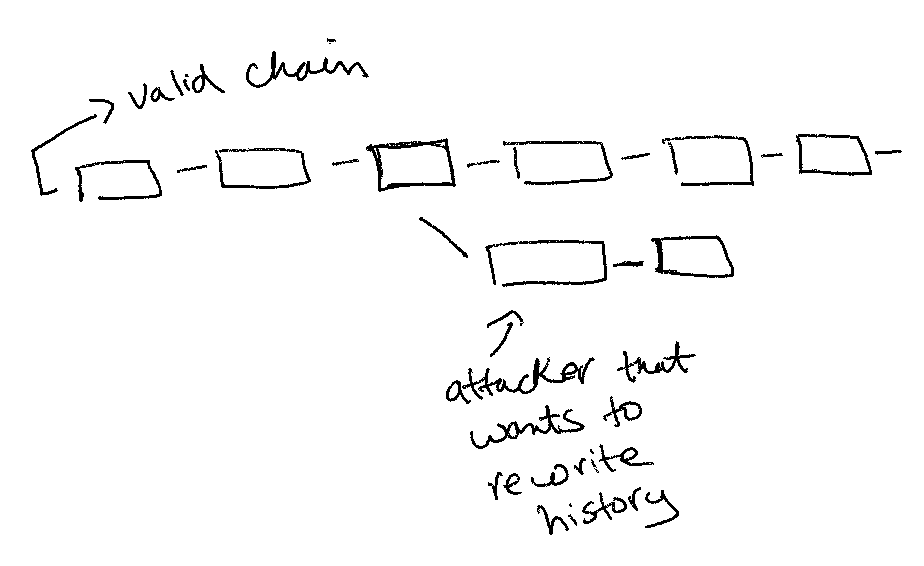
Once a new block with a valid hash is successfully produced, the only way to rewrite that block (i.e., rewrite the transaction history) is to redo that computation work again. Every new block that gets produced on top of this new block increases the work needed to rewrite that previous block because it would require redoing the work on all the blocks after it. The cost of doing this increases exponentially with each new block added onto the chain.
“the work to change the block would include redoing all the blocks after it.”
Satoshi explains how this approach prevents nodes from trying to subvert the network by spinning up a bunch of different IP addresses and pretending to be multiple nodes at once. If a person can spin up multiple nodes at once, it allows a single node to fraudulently cast multiple votes for what the next block is.
“The proof-of-work also solves the problem of determining representation in majority decision making. If the majority were based on one-IP-address-one-vote, it could be subverted by anyone able to allocate many IPs.”
This type of attack cannot happen in proof-of-work because each node is required to expend CPU power to cast a vote.
“Proof-of-work is essentially one-CPU-one-vote.”
In other words, in order to “vote” the next block into the network, a node needs to physically compute a hash that meets the criteria of having the right number of bits. This physical limitation prevents a lot of potential attack vectors that traditional consensus algorithms are plagued with, thereby simplifying the whole system.
“To modify a past block, an attacker would have to redo the proof-of-work of the block and all blocks after it and then catch up with and surpass the work of the honest nodes.”
Of course, this solution comes at the cost of expending physical energy for every block, but we will get into that later.
Satoshi goes on to explain the concept of block “difficulty.”
“To compensate for increasing hardware speed and varying interest in running nodes over time, the proof-of-work difficulty is determined by a moving average targeting an average number of blocks per hour. If they’re generated too fast, the difficulty increases.”
Let’s translate that.
As we just learned, nodes need to produce a correct hash that meets the required criteria of having the right number of zero bits. The more compute power a node has, the faster it can churn out hashes until it finds the right one. Moreover, the more nodes there are in the network, the faster the right hash will be produced because more nodes are trying to find the hash at the same time.
To compensate for the “increasing hardware speeds and varying interest in running nodes over time,” Satoshi proposes the concept of “block difficulty,” where the difficulty to produce the correct hash increases if the blocks are being produced too fast (and vice versa, difficulty decreases if the blocks are being produced too slowly). This difficulty is adjusted automatically by the Bitcoin algorithm.
This is why Bitcoin produces a block every 10 minutes (on average). If a block ends up being produced faster or slower, the difficulty is adjusted so that the next block gets produced after 10 minutes.
Phew. You just learned the core of the Bitcoin protocol, and you probably have a lot of burning questions. If you do, please don’t hesitate to shoot them at me.
In the next lesson, we will learn about how nodes in the Bitcoin network coordinate and communicate to accept the next block into the longest chain. Stay tuned!






Add Comment